




The Quick ‘Fix’ With a Real-World Example
When it comes to the many things you can see in Google Search Console, ‘alternate page with proper canonical tag’ can be one of the most confusing. Fortunately, the explanation, and “fixing” it, is is actually pretty straightforward.
This warning means that Google has found a duplicate page on your site which correctly has a canonical tag to the main or original URL.
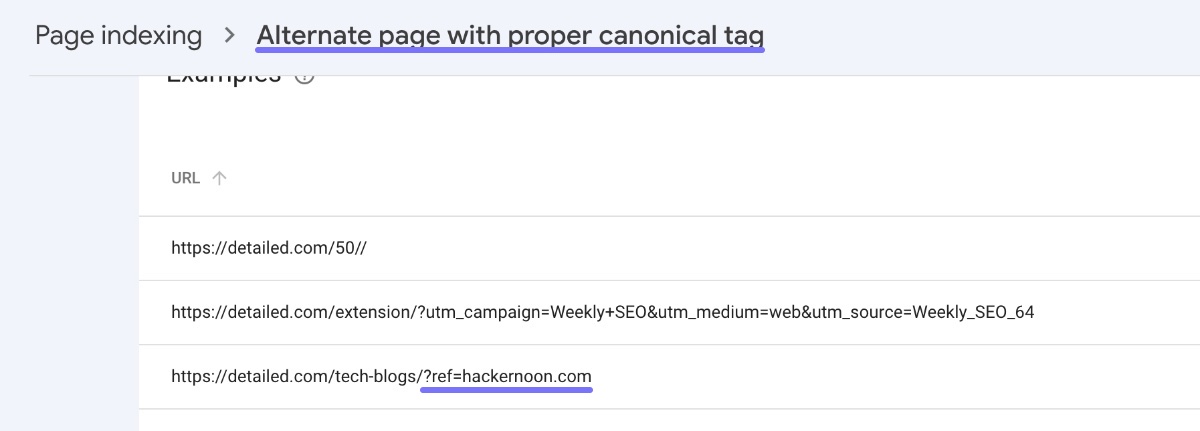
For instance, one of the pages which shows up in my ‘Alternate page with proper canonical’ report is:
https://detailed.com/tech-blogs/?ref=hackernoon.com
If we go to this page, we can see it has a canonical tag of:
https://detailed.com/tech-blogs/
That tech-blogs page has a self-referencing canonical tag (the canonical tag points to itself, as it should), therefore Google has found an alternate page with a proper canonical tag.
That’s why it showed up in my report.
So how do you fix this?
Well, there are actually no problems here, and nothing at all I need to fix.
Let me explain…
What happened is that a website, Hackernoon, linked to a page on our website and added ref= to the URL when doing so. There’s absolutely nothing we can do about that. We can’t control how other websites link to us.
If you go directly to that URL on our website, we can use the Detailed SEO Extension (100% free) to see that it has a canonical tag to the ‘clean’ version of the URL.
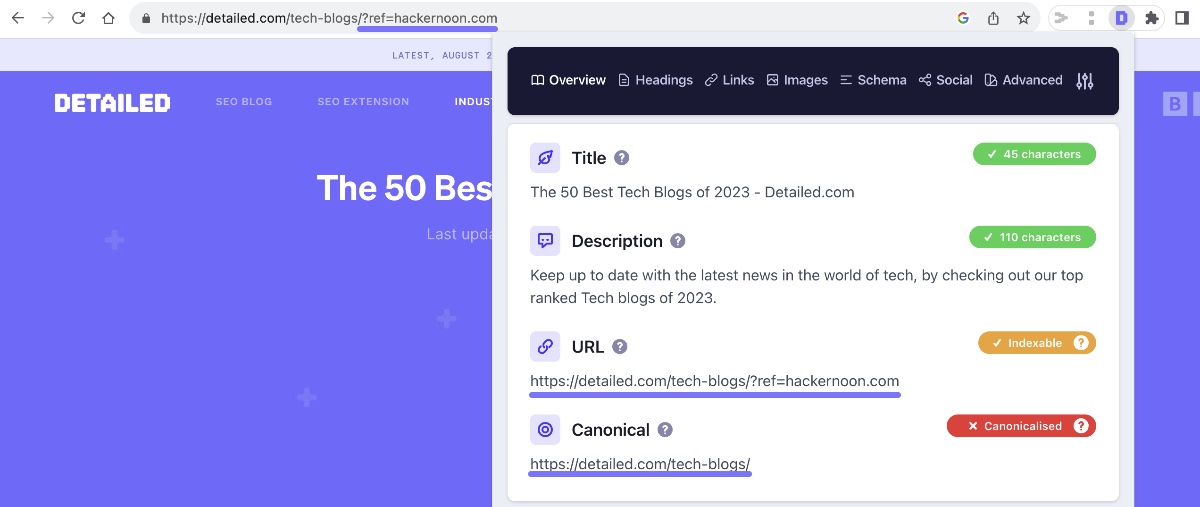
What that means is that this report in Google Search Console is not telling us, “Here’s a problem you need to fix” but rather, “Here’s something we came across and we’re just letting you know what we found.”
Now, this report isn’t totally just a random list of URLs you can do nothing about.
It may be the case that you’re internally linking to pages which canonicalise elsewhere, which is something you can control.
For instance, if I was linking from the homepage of Detailed to /tech-blogs/?ref=hackernoon.com, that’s pretty odd and not a link I should have in place. I should be linking straight to /tech-blogs/.
If you want to understand these terms in more detail, let’s keep going by explaining exactly what a Canonical Tag is.
What Is a Canonical Tag in SEO?
A canonical tag is also known officially as a “rel canonical,” and it’s a tag in the page’s source code that tells Google (or any other search engine) that a master copy of that page exists.
This can prevent search engines from flagging sites as spam for having duplicated content. The canonical tag is important because it tells Google which version of a URL you want to be shown to users in search results.
You may think, “Why would I even create duplicate pages?” Well, you may not. The problem lies in the fact search engines can see slightly different versions of the same URL as a unique page. For example, https://www.yourwebsite.com, http://www.yourwebsite.com, and https://yourwebsite.com are seen as different URLs to Google.
Since most sites are automatically tagged, many website managers or owners don’t even realize which pages are being displayed to Google and which aren’t. This can cause search engines to index and show multiple versions to the same content, which are all perceived in algorithms as duplicate content.
Setting a rel canonical tag establishes hierarchy and clarifies a page’s position and purpose on your site.
How to Find the Canonical URL for Any Page
There are three options you have here. They’re all free and easy to follow.
#1
Use the Free Detailed Extension for Chrome and Firefox
After auditing over 1,000 websites and wanting a quick way to identify issues with them, we created the free Detailed SEO Extension for Chrome and Firefox.
As I write this it has over 180,000 weekly users.
Once it’s installed, use the video on the extension page to learn how to ‘pin’ it to your address bar. Then, for whatever page you want to see the canonical tag, simply click on the ‘D’ icon as shown below.
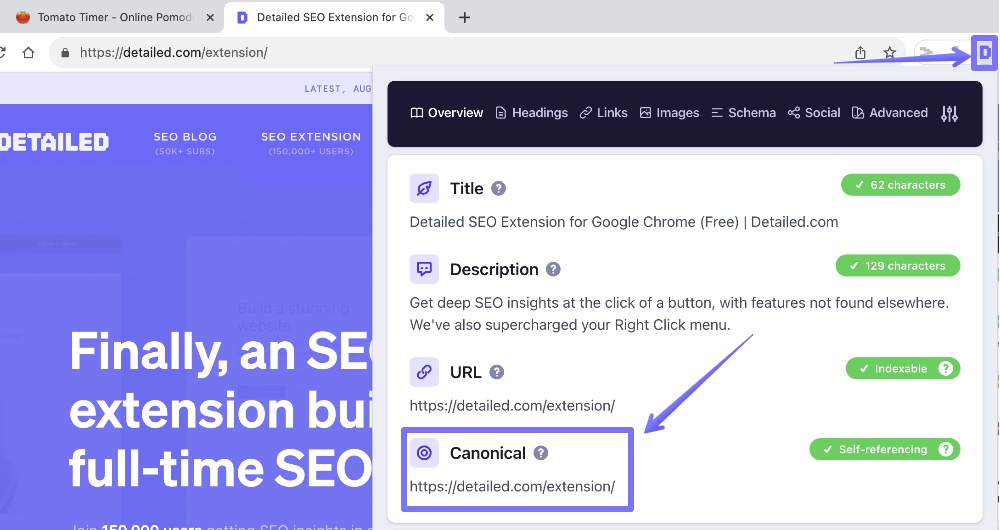
That’s it. You now know the canonical URL of any page you’re on.
#2
Find the Canonical URL in the Source Code of a Page
If for whatever reason you don’t want to use our extension, you can find a canonical URL manually by looking at the source code of a page.
To do this, Right Click anywhere on the page you’re on, and select ‘View page source’ as shown in the image below.
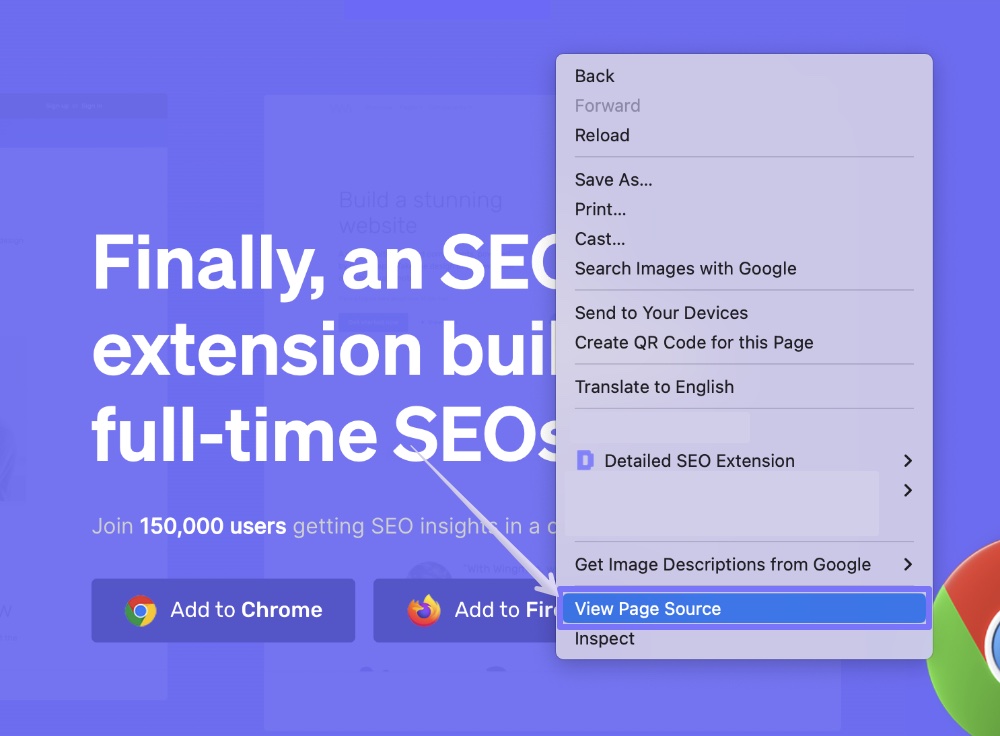
From there, you’ll want to select CTRL+F (Windows) or CMD+F (Mac) on your keyboard, and look for the word ‘canonical’.
If there is a canonical tag present, you should find the accompaning URL via this route.
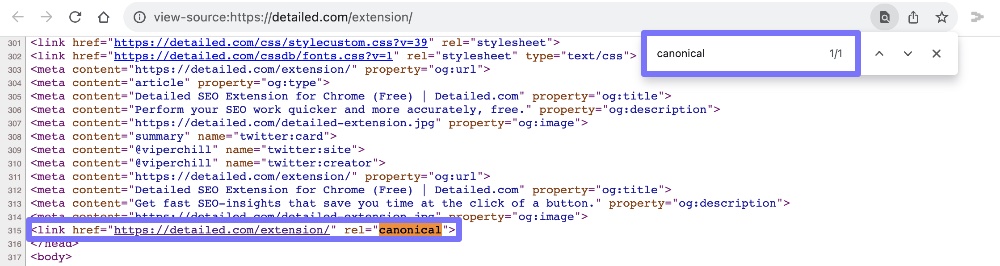
We can see in the screenshot that a canonical URL is present and that it’s the same URL as the page that I’m on.
#3
Find a Page’s Canonical URL in Google Search Console
While this step is useful to know, it only reflects the canonical URL of the last time Google crawled a page, and not necessarily what’s currently live on a website.
Once you have Google Search Console open, enter the URL of the page you want to check the canonical tag in the search box at the top.
Then, on the resulting page, click on ‘Page indexing’.
If you scroll down, you’ll see both the canonical tag of the page and the canonical tag that Google has selected.
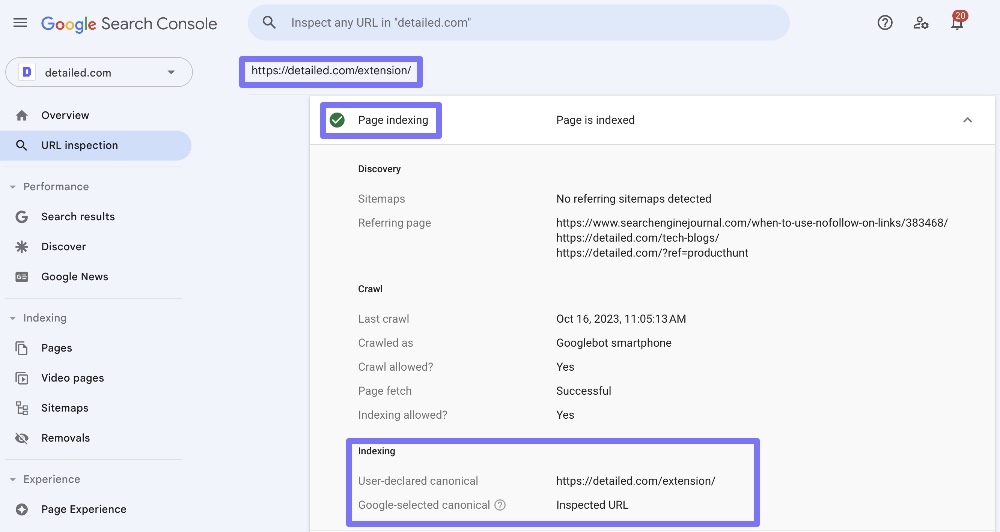
In the example above, we can see that our extension page has the same canonical tag as its URL (known as a self-referencing canonical) and Google has respected what we chose.
So, How Do You Fix An Alternate Page With Proper Canonical Tag?
This report from Google Search Console isn’t a bad thing, and there’s really nothing you need to do on your part in most cases.
Pretty much every website on the internet will have URLs show up on this report.
The exception would be if the page you’re referencing as a canonical URL, which isn’t the page you’re on, isn’t a page you’re trying to index in Google.
At the same time, you should make sure any alternate pages that are referencing a different URL as a canonical URL are supposed to do that. It may be the case that you want them to reference themselves.
Finally, if you don’t want a duplicate page to reference a different URL via a canonical tag, you can use a 301 or 308 redirect instead. This causes a URL to permanently redirect users to another one in its place. It’s helpful for SEO because it removes ranking authority from an old URL and directs it to a new one, where all of the “weight” of the previous URL should be passed on.


