




To The Point: Rel=”Canonical” HTML Code
<link rel=”canonical” href=”https://detailed.com/extension/” />
I often need to copy and paste this myself, so let’s save everyone some time and put it right at the start of this guide.
A Definition of Canonical Tags
Having duplicate content without a user-selected canonical on your site can harm your search engine rankings whilst also burying some of your best pages. Even if you’ve been diligent about ensuring that the text on most pages of your site are unique, you could have duplicate content without even knowing it.
To help site owners avoid duplicate content, the three major search engines (Google, Yahoo!, and Bing) banded together in 2009 to create canonical tags.
You may have noted that your page has an issue with canonicalization or is missing a self-referencing canonical. So, in order to help you understand what steps to take next, we need to know exactly what is the definition of a canonical tag? In the words of Google:
When multiple pages have similar content, search engines consider them duplicate versions of the same page. For example, desktop and mobile versions of a product page are considered duplicates. Search engines select one of the pages as the canonical version and crawl that one more, while crawling the other ones less.
This guide will explain in detail, the various aspects of canonical tags including what they are, why you need to implement them, and common mistakes to avoid.
What is the Purpose of Canonical Tags?
From a search engine perspective, canonical tags merge two or more pages into one. The process works by specifying one master page as the canonical URL or the preferred version that the search engines should display in their results.
By definition, canonical means following a principle or rule. Usually, the context is religious, but in this case, it has to do with how search engines order pages that they crawl.
In short, a canonical tag is a link that tells search engines which page is the authority. This URL is the one that you want Google and the other search engines to index and rank.
Canonical tags are assigned with a simple HTML element in the page’s source code — also called a rel=canonical element, the code looks something like this:

This snippet of code is placed in the header tag of any page, and will let the likes of Google know that there is a ‘master’ version of this content. Search engines should then allocate all their ranking love to the designated page.
Any URLs that show similarities in terms of content or purpose to the original should tell Google (through a canonical tag) that they’re not the primary page and indicate that the intended ranking page is the one that should get the attention.
Why Canonical Tags Are Important
Canonical tags can help to solve the issue of duplicate content. Often duplicate content is thought of as plagiarism or scraping, but in most cases, this problem is internal.
Duplicate content can occur because of two things:
- A single page can be accessed using multiple URLs.
- There are different URLs with similar (or the same) content.
While Google might not “penalize” a webiste for these instances, they can still be detrimental to the site overall.
Here’s why:
- Duplicate content can bloat your site, making it more difficult and time-consuming for Google to crawl. As a result, your best-quality, unique content might not be properly indexed and ranked.
- Duplication can also adversely affect your search engine rankings. If you have multiple pages that are similar, Google will “guess” which one is the master, which can result in one of two things:
1 – Google picks the page it thinks is the main page and ranks that highest, causing the other pages to rank lower or not at all.
2 – Google weighs all the duplicates equally, which ends up diluting your ranking in search results.
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin. Examples of non-malicious duplicate content could include:
- Discussion forums that can generate both regular and stripped-down pages targeted at mobile devices
- Store items shown or linked via multiple distinct URLs
- Printer-only versions of web pages
If your site contains multiple pages with largely identical content, there are a number of ways you can indicate your preferred URL to Google. (This is called “canonicalization”.)
How Canonical Tags Are Used
If you have a multi-page website and there is overlapping or similar content on some of the pages, then search engines could have a tough time figuring out which page they should serve up to people searching for your topic or keyword.
As a result, the pages can compete with each other, and the likes of Google may end up rotating the pages in search results. If no single page dominates, then the pages may not reach their full ranking potential. Unless, of course, there is a canonical tag in place.
A canonical tag solves this problem by telling the search engines which page should dominate. Each page would have a canonical tag, but the other pages would have a specific canonical tag that points to the dominant page.
As a brief side note, it’s worth noting however, that a rel=”canonical” is a request to Google, rather than a directive:
It’s a hint that we honor strongly. We’ll take your preference into account, in conjunction with other signals, when calculating the most relevant page to display in search results.
So Google can, if they wish, ignore this signal if they feel another page is more relevant.
When to Canonicalize Content
Current best practices include canonicalizing every page on your site, even though Google says it isn’t mandatory to do so.
Having a canonical tag on each page is something we generally look to do on the pages of Detailed.com:
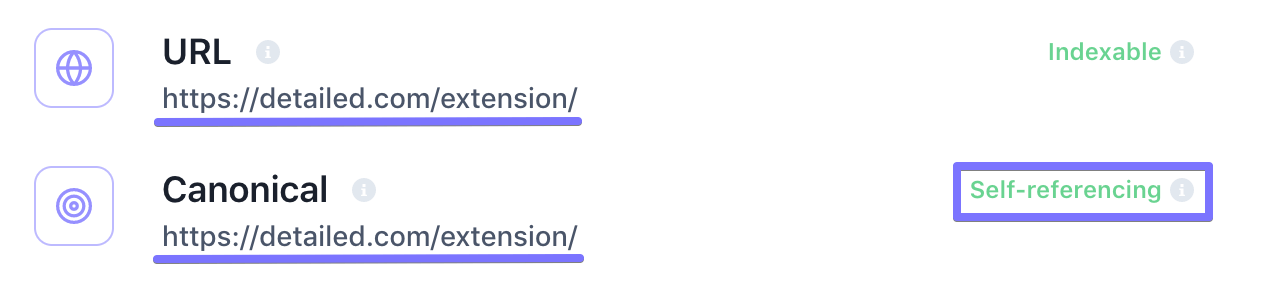
However, at a minimum, you should canonicalize pages when any of the following apply:
- Pages have content that is extremely similar, or it’s an exact duplicate.
- You updated a piece of older content. You don’t necessarily want to block people from seeing it, but you don’t want to send people to it, either. You want people to see the new piece of content instead.
- The content serves the same search intent. For example, you might have a series of service pages, but you also describe those services in detail on your home page. You might prefer someone searching for that service to land on your home page, not the service page.
- You have expiring content such as a special or an event. You still want the page to be visible if someone gets to it from an external link, but you don’t want it to appear in search results. In this case, you would specify a canonical link, making the updated page the master.
In terms of Google’s specific advice on when to use a canonical tag, they state:
If you have a single page accessible by multiple URLs, or different pages with similar content (for example, a page with both a mobile and a desktop version), Google sees these as duplicate versions of the same page. Google will choose one URL as the canonical version and crawl that, and all other URLs will be considered duplicate URLs and crawled less often.
If you don’t explicitly tell Google which URL is canonical, Google will make the choice for you, or might consider them both of equal weight, which might lead to unwanted behavior
In some situations, a 301 redirect, rather than a canonical directive, is the best option. A 301 redirect simply redirects a user from an old page to a new one. These 301 redirects are common on ecommerce sites when a product sells out or is discontinued — as instead of deleting the page outright, an ecommerce site could redirect the URL to a similar product or a category page.
Another reason to use a 301 redirect would be to phase out an old piece of content entirely and send the user to an updated version.
Other Scenarios Where Canonical Tags for SEO Are Important
Ecommerce and Blog Categories
Another scenario that would require the use of canonical tags is when you have categorical pages, or search, or sorting functions.
An example of this is a blog that utilizes categories to sort and organize content. A blog post might have a direct URL, and it might also be part of one or more categories. Those categories would also have the category name in the URL.
Or, let’s say you have search enabled on your website, a search query could return the name of the search in the URL.
Another instance is if you have an ecommerce store and your products belong in multiple categories with multiple variations. Each of these categories and variations may end up having a unique URL.
Syndicated Content
Canonicals tags are also essential for guest posts Imagine for a moment that you’re a guest blogger, and you’ve created a Pulitzer-prize worthy piece of content for someone else’s site.
You could still publish it on your site to share with your audience (barring any contractual agreements prohibiting this behavior) as long as you use a canonical tag on your blog that points back to the original source. This is also how publishing sites like Huffington Post, Forbes, Inc., etc. can syndicate other people’s content. They often copy an article or press release word for word and then (in theory) assign a canonical tag that points back to the original source.
URL Parameters
A scenario that’s often overlooked is URL parameters. For example, if you’re tracking the performance of an ad campaign, then you might have multiple URLs set up pointing to the same page. You should specify a single master page with canonical tags to prevent SEO issues with duplicate content.
How to Avoid Being Penalized for Scraping
One thing that’s tough to control is other people stealing your content, and you shouldn’t be penalized for that. Though you can’t put a canonical tag on someone else’s site, you can do something even better that signals to Google that the content you’ve created is yours.
You have the option to submit your URL in Google Webmaster Tools to ensure it is indexed. This can tell Google that your post is the original content, and it was in place first. Anything else created afterwards and published on another site, should in theory be treated as a copy.
Common Mistakes People Make When Implementing Canonicalization
Setting up canonical tags is easier than ever. Thanks to plug-ins, apps, and built-in functionality, most CMS’s make them fairly easy to implement. You can, of course, also create them manually by adding a rel“canonical” tag in each page header.
Still, mistakes happen, so we’ll address the most common:
- Don’t block Google from crawling the duplicate pages. If you use the robot.txt to block Google from crawling the duplicate page, then Google won’t see it all. That means you lose any ranking signals that could help the original page, like links, engagement, etc. The same goes for telling Google not to index it. The better practice is simply to indicate to Google that there is a duplicate.
- Do canonicalize your home page (or every page for that matter). Recently, Google publicly recommended that whilst not critical, webmasters should be using self-referencing canonicals even if you don’t think there’s a duplicate. This is especially important for your home page, which could potentially be accessed via multiple URLs, such as:
– http://home.com
– https://home.com
– http://www.home.com
– https://www.home.com - Don’t leave off important information. It’s not uncommon for people to leave the HTTP or HTTPS off of their links, rationalizing that the links still work. However, this information is important to Google. With few exceptions, Google prefers HTTPS as the canonical. This, of course, is assuming that you’ve made the switch to SSL and are on a secure domain. Though, the most important thing is to make sure that the canonical URL you use is valid.
- Do use lowercase URLs only (assuming the correct version of the page features all lowercase letters in the URL). This might seem nitpicky, but Google distinguishes between capital and lowercase letters, viewing two identical URLs (with the exception of capitalization) as different entities.
- If a site uses hreflang links for different language variations of a page, then ensure that the canonical URL is pointing to the correct page for that respective language or country.
- Ensure that you are not pointing the canonical URL to a different domain, as both Yahoo and Bing don’t allow this.
Conclusion
Remember, even if you didn’t set out to create duplicate content, there are multiple scenarios that could still signal to search engines that there’s an issue.
As canonical tags are slightly technical, many people can find them intimidating, and ignore them altogether to the detriment of their search engine standings.
Now that you know the basics of why canonical tags are essential and how to use them, we hope you can resolve any existing duplicate content issues on your site.


