




How to Resolve This With a Real World Example
Th ‘Crawled – currently not indexed’ status under the Page indexing report in Google Search Console is a signal from Google that, while its bots have crawled and recognized your page, it hasn’t been added to their index.
Google won’t include this URL in their search results. A scenario which can be a painful, especially in an era where you rely on digital visibility for success.
But what does this status mean, and how can you fix it?
There are exceptions to everything in SEO, but this report generally means that content simply wasn’t good enough for Google to index it.
This can mean you have duplicate pages, spammy or hacked pages, or pages that – for whatever reason – have been deemed to have very little value.
Because Google don’t try to index every single URL on the web (an expensive business), they try to focus on having more quality pages in their index.
We can look at this report for Detailed to see what kind of URLs are showing up:
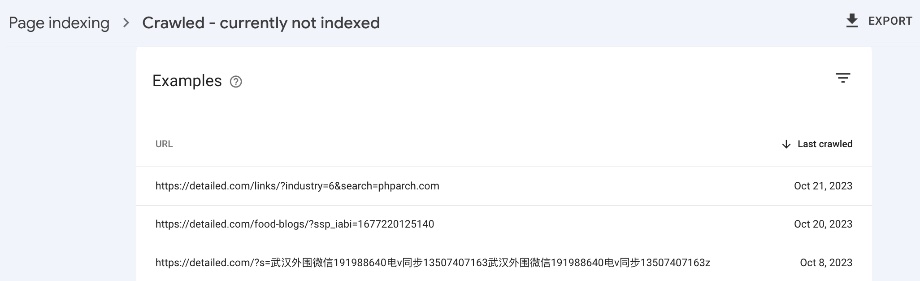
These three example URLs are actually perfect for an explanation.
The first is a page that no longer exists but when it did, had very little content on it.
The second is a duplicate of another page, and Google is finding it due to another website linking to us in this way.
The third is a remnant from when our website was hacked, and tens of thousands of spammy search pages were somehow created and linked to from other websites on the internet.
Possibly as part of some kind of negative SEO attack.
You can verify this by clicking on the ‘Inspect URL’ icon and looking at ‘Referring page’, as shown below:
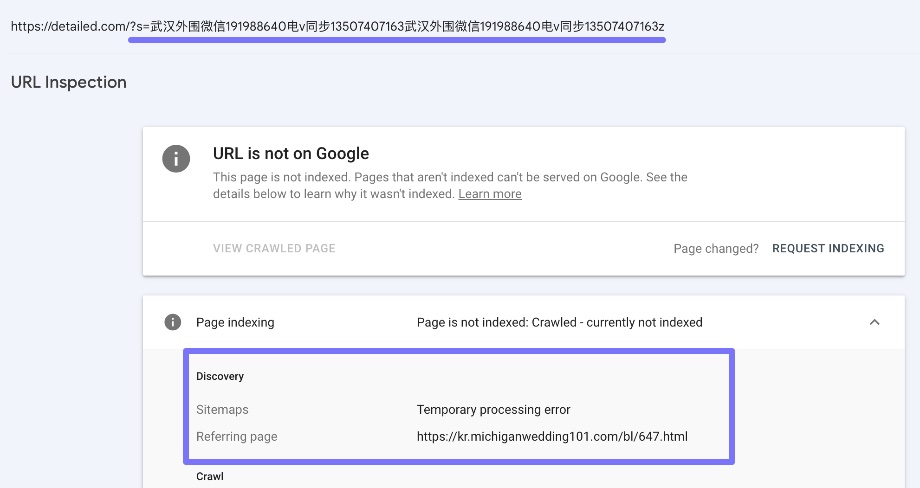
The key thing about all of these example URLs is that they are low quality and are rightly being kept out of Google’s index.
If you learn of URLs like this on your own site you can remove them so they give a 404 status code, improve them, redirect them elsewhere or make sure they have proper canonical tags in place.
If that is already in place – such as some pages for us already being taken down – then there’s nothing more you need to worry about.
Of course, you’ll be in a better position to know if a page is something that can and should be improved, or it’s a page that shouldn’t exist, and so on.
In many cases you actually won’t need to take any kind of action at all, and in other cases you’ll see pages to take care of in some form.
If you would like to learn more about this entire system, let’s keep going by starting with the basics.
What Does “Crawled – Currently Not Indexed” Mean?
When you upload new content to the web, Google dispatches automated bots known as crawlers or spiders to ‘crawl’ and review the content. This is a process of discovering and analyzing new or updated pages. Once a page is crawled, it is then queued to be added (or indexed) to the search engine’s database, making it discoverable through search queries.
The status “crawled – currently not indexed” in Google Search Console denotes that Google’s bots have successfully crawled your page, but for some reason, the page has not been added to Google’s index. Simply put, Google knows your page exists, but it won’t appear in search results.
Reasons Behind Crawled – Currently Not Indexed and How to Fix It
Fixing the “crawled – currently not indexed” status in Google Search Console hinges on identifying the root cause. Different issues warrant different solutions, and without addressing the underlying problem, the status may persist.
Below, we will delve into the potential causes of this status and provide actionable steps to prompt Google to index your pages.
Poor Internal Link Structure
When a page within your site lacks internal links, it can obstruct crawlers from accessing, understanding, and indexing certain parts of your site. Google sees pages that are not adequately linked as less important or even orphaned (pages without any links pointing to them), reducing their chances of being indexed.
To address the issue of orphan pages, find an existing page on your site that relates thematically to the page you want Google to index. Within that content piece, find an appropriate section and integrate a link pointing back to the previously orphaned page.
This simple act facilitates the indexing process and enhances user navigation by providing more comprehensive and interconnected content.
Thin Content
Google might view pages with scanty word counts as “thin content,” implying they lack depth or sufficient information. If your content is significantly shorter than comparable top-ranking pages, it risks being sidelined during indexing. For instance, if competing search results delve deep with over 3,000 words and your page only offers a few hundred, Google will perceive it as inadequate.
To rectify the thin content, enrich the page with relevant and detailed information. Aim for a comprehensive yet concise presentation of the topic, ensuring it offers value to readers. Google will recognize such efforts, leading to improved search rankings.
Content That Doesn’t Match the Search Intent
When content doesn’t align with what users are searching for, it’s said to mismatch search intent. Google prioritizes delivering results that best meet users’ needs. If your page’s content doesn’t match the expectations set by its title, keywords, or meta description, Google will likely bypass it in indexing.
To address this, research popular queries related to your topic. Adjust your content to better answer those queries, ensuring the title, headers, and descriptions accurately reflect the core content.
Duplicate Content
Duplicate content refers to substantial portions of content appearing in multiple web locations. When Google detects this, it may choose to index only one version, deeming the others redundant. This choice can lead to certain pages being tagged as “crawled – currently not indexed.”
To remedy this, ensure each page on your site offers unique value. Utilize tools like Copyscape to check for content replication. If you identify duplicates, modify the content to make it distinct or use canonical tags to signal to Google which version should be considered the primary source, ensuring proper indexing.
Technical Issues
Technical glitches can be a primary reason behind the “crawled – currently not indexed” status in the Google Search Console. Factors like “noindex” tags instruct search engines to bypass the content during indexing. Similarly, a blocked robots.txt file can restrict crawler access, and server issues might make the page inaccessible during a crawl.
Regularly audit your site for these technical pitfalls. Ensure that no “noindex” directives are unintentionally present. Verify that your robots.txt file isn’t obstructing essential pages, and regularly monitor server health and uptime to guarantee accessibility for search engine crawlers.
In Summary
In the evolving SEO landscape, understanding the reasons behind the “crawled – currently not indexed” status in Google Search Console is crucial for web visibility. Whether caused by content issues like thin or duplicate content, misalignment with search intent, or technical roadblocks, addressing the root causes is essential.
Regularly auditing, refining, and aligning your content with genuine user intent while rectifying technical hindrances can significantly enhance your site’s chances of being indexed favorably by Google. A proactive approach ensures your content reaches the search engine’s database and your target audience.


