




A Real World Example and How to Fix It
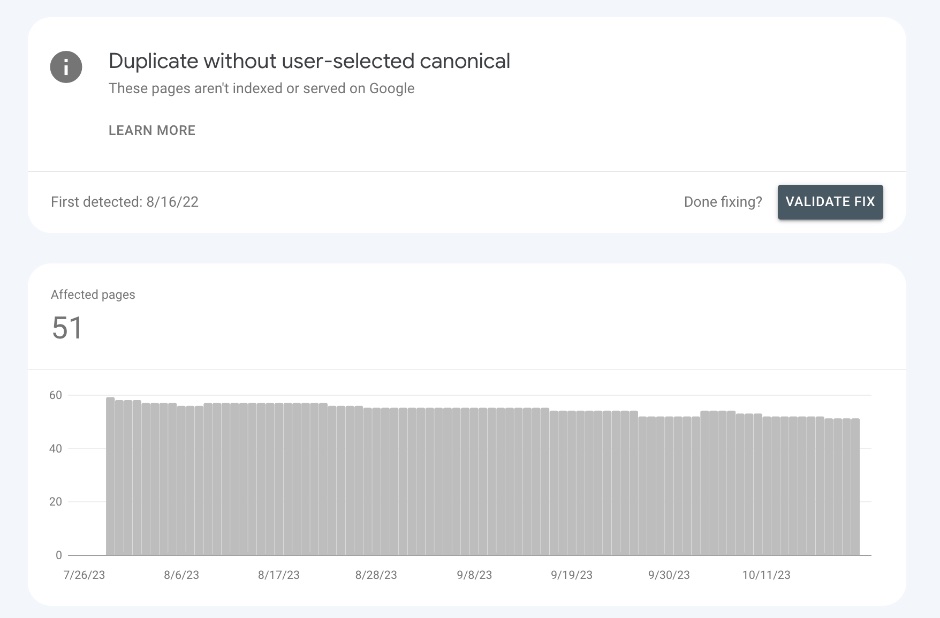
If we load up Google Search Console, head to Page indexing and click on the ‘Duplicate without user-selected canonical’ report, we see Detailed has 51 pages which fit this criteria:
Scrolling further down the page, we can see exactly which URLs are involved here:
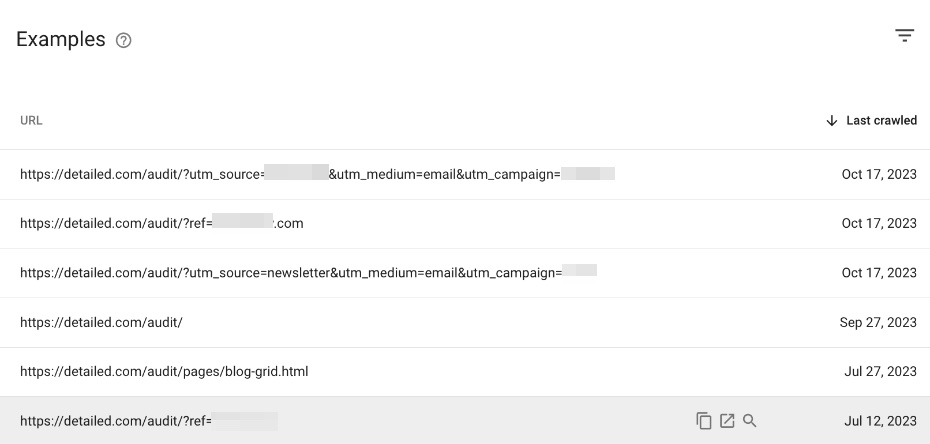
If you look closely, you’ll notice that all of these URLs originate from the /audit/ directory on our website.
What Google is essentially saying is that these are all duplicates of another page on our site, and they don’t have a canonical tag in place.
The reason this has happened is my own fault.
The majority of Detailed is powered by WordPress, a popular content management system. There are various plugins you can use to ensure things like canonical tags are in place across the entire site very easily.
For our /audit/ landing page however, we’re not using a WordPress. It’s a static HTML landing page.
The majority of the URLs showing up here are simply because I forgot to put a self-referencing canonical tag on the main page.
It’s not a huge deal, and something we’ve already taken care of.
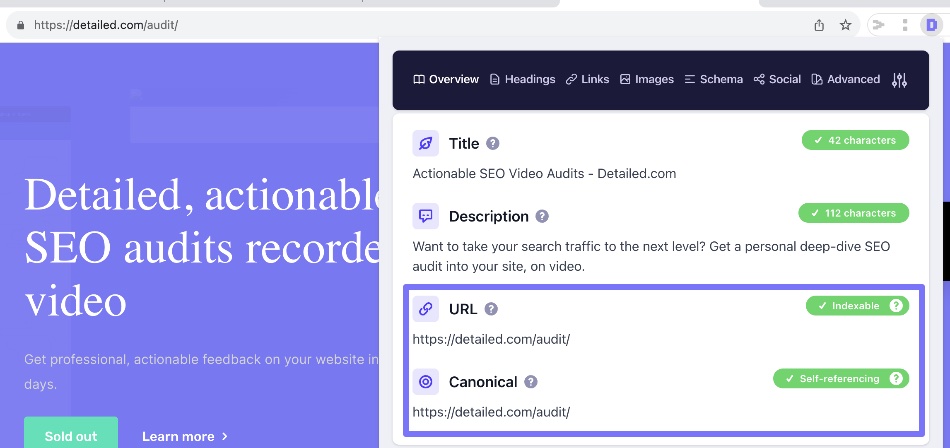
Therefore, your main takeaway from the URLs Google are reporting here is that Google don’t see a canonical tag on “master” or main version of a page and all of the duplicate variations they’ve found for it.
Not all of our warnings here are for a single page, so there are other issues we had to clean up, such as removing HTML templates which weren’t supposed to have been uploaded on our server.
We pride ourselves on giving real world examples to issues and what the fix is, but we know some people are learning SEO and want to dive deeper into a topic as well.
We’ve done exactly that below.
What Does “Duplicate without User-Selected Canonical” Mean?
This status means Google’s crawlers discovered identical or very similar content existing on multiple URLs of your site. However, there were no clear signals about which URL you want indexed as the main “canonical” version.
With no canonical tag, Google doesn’t know which duplicate page to prioritize in search results. So it ends up not indexing any version of the content.
For example, imagine you have a blog post that exists on three separate URLs:
- example.com/blog/how-to-bake-cookies
- example.com/recipes/how-to-bake-cookies
- example.com/desserts/how-to-bake-cookies
The post content is identical across each URL. But you haven’t indicated anywhere that, for instance, the /blog/ version should be treated as the primary page.
In this scenario, Google discovers the duplicate content but there is no user-selected canonical page. This triggers the “duplicate without user-selected canonical” status, and Google will refuse to index any version of the post.
When Does Google Show This Status?
There are several key reasons you may get this message in the Search Console:
1. Accidental Duplication
It most often occurs when the same content gets published across multiple URLs unintentionally. For instance, entire blog posts or articles are copied to various sections of a site by mistake.
2. No Canonical Tags
The duplicates themselves aren’t necessarily an issue. The bigger problem is not using HTML canonical tags to specify the URL you want indexed.
3. Site Migrations
Migrating domains can create duplication between old and new sites if redirects aren’t fully implemented.
4. URL Structure Changes
Introducing or altering parts of URLs such as dates, categories, or filters may inadvertently lead to duplicate content.
5. Technical Problems
Backend issues like CMS bugs, caching errors, misconfigured servers, etc. can also create hidden duplicate content.
Essentially any scenario resulting in unintended duplication where canonical tags are missing can trigger this status.
Checking for Duplicate Content
There are a few ways to detect duplication issues proactively:
1. Google Search Console
Check for any URLs listed under ‘duplicate without user-selected canonical in the Index Coverage report, as we’ve covered here. You can also look into reports such as ‘Alternate page with proper canonical‘.
2. URL Inspection Tool
Inspect specific pages to see if Google has selected its own preferred canonical URL.
3. Site Audits
Use crawling tools to identify duplicate titles, meta descriptions, etc. across your site.
Regularly monitoring these signals enables you to catch and fix duplications before they become problematic.
When Is Duplicate Content Acceptable?
It’s important to note that similar content across separate URLs is not always bad. There are cases where allowing intentional duplication improves the user experience and aligns with site architecture:
- Product descriptions accessible through various categories
- Blog posts are reachable via multiple sections
- Location-specific versions of the same content
For strategic duplication, you have a couple of options:
- Implement self-referring canonical tags
- Create unique titles, meta descriptions, images, etc. to help differentiate
- Slightly adjust the duplicate content on each URL
However, in general, you still want distinct, one-of-a-kind content for every new page on your site. Avoid excessive duplication that dilutes your content quality.
Fixing ‘Duplicate without User-Selected Canonical’
When this status appears in Search Console, here are some ways to resolve it:
1. Add Canonical Tags
Implement canonical tags to point all duplicates to one preferred URL you want indexed. Use self-referring canonicals where you want multiple versions indexed.
2. Do 301 Redirects
Redirect any unnecessary duplicate pages to the canonical URL using 301 redirects.
3. Try “noindex” Tags
Adding “noindex” to unneeded duplicates tells Google not to index those versions.
4. De-Duplicate Content
Remove or update duplicate pages to make them distinct enough to warrant separate indexing.
5. Update Sitemaps
Specify your preferred URL in XML sitemaps as an additional signal to Google.
Taking control of canonical signals is the key to fixing indexing errors from duplicate content.
Best Practices for Handling Duplicates
Here are some tips to improve duplicate content management:
- Craft unique content for each new page
- Implement internal linking and canonical tags at scale
- Strengthen technical SEO foundations to prevent backend duplications
- Do ongoing site audits with duplication detection
- Create distinct title tags and meta descriptions for all pages
- Avoid excessive copying or repurposing of existing content
- Understand URL structures to prevent duplication during migrations or changes
With a sound content strategy and technical SEO, you can minimize duplicate content pitfalls.
The Bottom Line
The “duplicate without user-selected canonical” status simply indicates that Google found duplicate content without clear instructions about which version to index.
While duplication isn’t always problematic, failing to handle it properly can lead to serious indexing and ranking issues. Implementing canonical tags is the most effective way to signal your preferred URLs.
Consistently optimizing for uniqueness while consolidating true duplicates will help avoid this status. With proper troubleshooting, duplicate content errors are easily diagnosed and corrected.


