




If you have ever seen the message “Indexed, though blocked by robots.txt” in Google Search Console then you may be wondering what that even means.
The Quick Fix
Using Google Search Console you can find all URLs which are included in the Indexed, though blocked by robots.txt report.
After searching for any URLs contained within the list that you do want search engines to crawl, you can edit the robots.txt file using one of the following methods (all explained below):
- Edit the robots.txt file directly using an SFTP client such as FileZilla
If you have a WordPress-based website:
- Yoast SEO
- RankMath
- All in One SEO
- Squirrly SEO
- If you have a Shopify store you can edit the robots.txt.liquid file
Once the file has been updated you can then return to Search Console to validate the fix.
What Is the Indexed, Though Blocked By Robots.txt Message?
In the most basic terms, Google has indexed a page that it cannot crawl.
To slightly expand on that, Google has been able to display these URLs in search results, despite the fact they are blocked by a robots.txt file that is in place on the site which prevents search engines like Google from crawling those pages.
One reason for this is that even though Google respects the robots.txt file, a page could still be linked to by other websites, causing it to be indexed. Google wouldn’t then crawl that page, but it can still appear in search results.
Here’s how that can look inside Search Console:
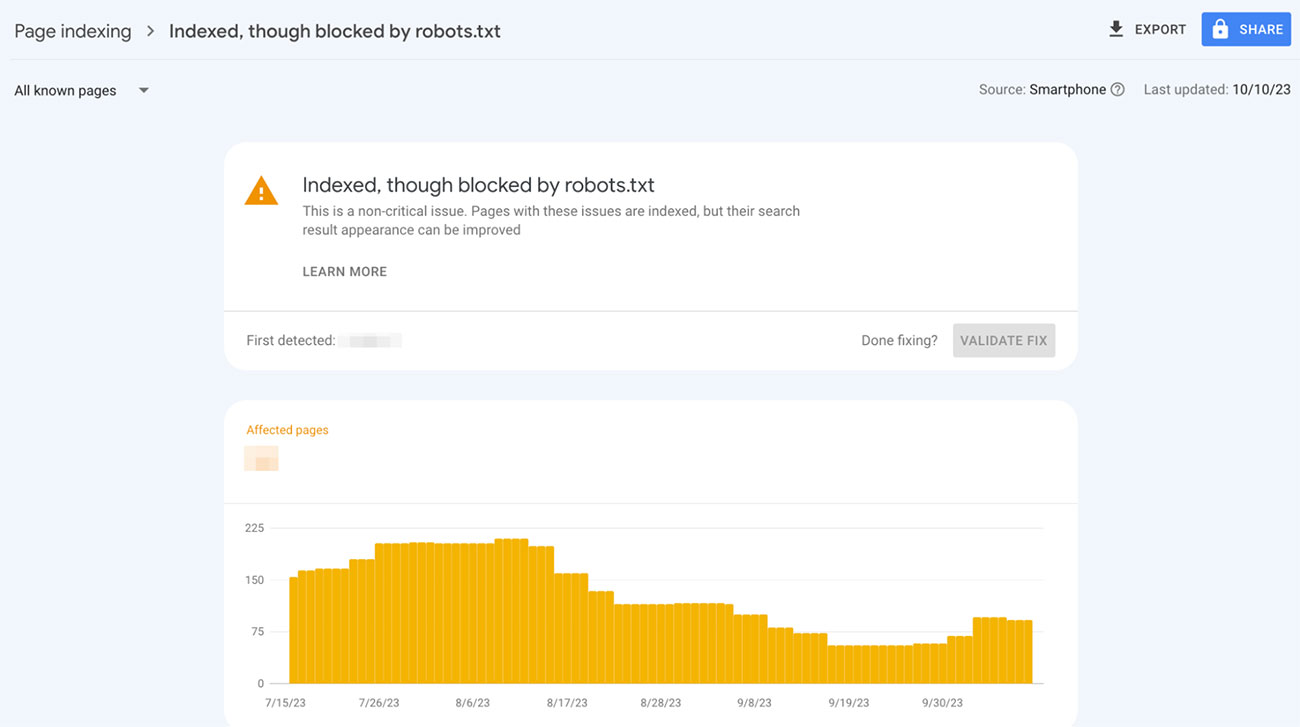
URLs appearing in this report are essentially Google’s way of bringing this to your attention as they’re unsure if you want these pages to be indexed or not.
This is not classed as a critical issue to have on your site, but it is likely something you will want to act upon. Which we’ll get to further into this article.
If you’re unsure why a specific URL is featured in that report, and you do want search engines to be able to crawl that page. You can click on the URL within the list, and then select “test robots.txt blocking” which appears in the right sidebar.
This will show you exactly what is blocking this page from being crawled, and if you want to correct that you can then go back and click to validate the fix once rectified.
First Things First, What is a robots.txt File?
So what exactly is a robots.txt file? This is essentially a type of text file on a website which contains a set of rules that search engines should follow.
This file could instruct the likes of Google to not crawl a specific page on a website, or even a set of pages contained within a directory on that site.
For example, whilst we want Google, Bing and other search engines to crawl Detailed.com, we may have a directory such as Detailed.com/designs (this doesn’t actually exist) that we do not want to be crawled.
Adding this directory to our robots.txt file would prevent crawlers from sending crawl requests for these pages. You can find Google’s official guidance on robots.txt file on this page.
If we look at a real-world example, here’s a small sample of a robots.txt file from Elle.com:
Disallow: /landing-feed/
Disallow: /oauth/
Disallow: /preview/
There are several directories which have been excluded from being crawled, such as /landing-feed/ and /preview/.
To be clear though, this simply stops these pages from being crawled, and not from being indexed in search results. This would need to be done by using a noindex meta tag, but that’s a whole other article. You can read more information on this topic on Google’s developer’s page.
How to Find the Source of the “Indexed, Though Blocked by robots.txt” Error
Using Search Console
You can quickly identify if you have this issue on your site using Google’s Search Console.
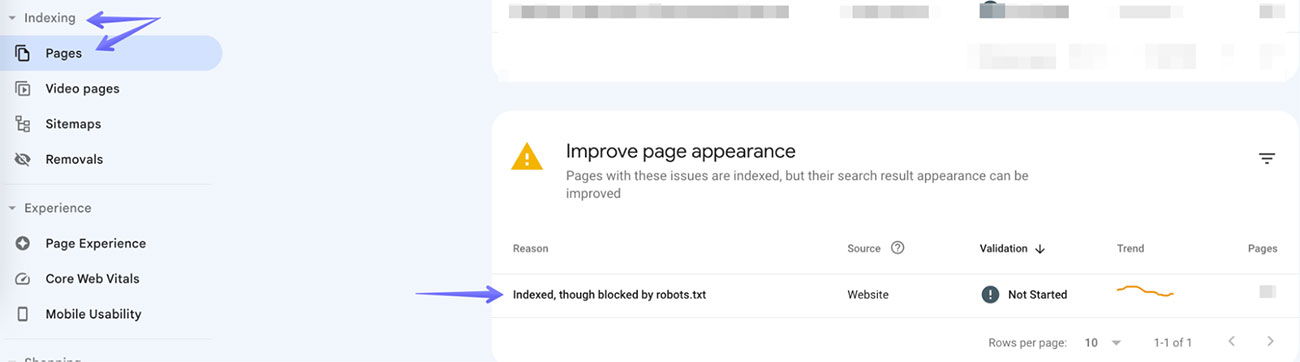
Under the Indexing dropdown on the left navigation bar, select Pages, then if you have the issue you’ll see a “Improve page appearance” section. Clicking on “Indexed, though blocked by robots.txt” will bring up a list of all pages impacted by this warning:
Google also has a free Robots Testing Tool which you can use to run a test on your robots.txt file.
This will display your robots.txt file as well as bring up any warnings or errors in place.
If you wish to test a certain page you can also enter this and run a URL-specific test:

There is also the option to change the user-agent from Googlebot to various other Google alternatives such as Googlebot-News or Googlebot-Image.
An alternative method to find this issue is by using a tool like RankMath which has a URL Inspection API Integration for Google.
How To Fix Indexed, Though Blocked by robots.txt Issue?
To fix this issue you should ensure that Google and other search engines can crawl the pages on your website that you actually want them to.
There are several routes you can take to correct this by using various tools. We’ve covered those options below so that you can select the best method for you.
As a disclaimer, be very careful when editing a robots.txt file if you are unsure of what you are doing(!)
We’ve witnessed sites cause themselves real problems in the past by editing these files incorrectly. For that reason, we’ve linked to more extensive guides from the providers of each method we cover below.
#1
Using Search Console
The first option would be to export the list of impacted URLs directly from Google Search Console.
You can then review this list to determine if there are any URLs featured that you would want search engines like Google to crawl. If that is the case you should look to update your robots.txt file and remove the disallow command to accommodate this.
#2
Edit robots.txt File Directly
There are a few ways you can do this. The first would be by editing the robots.txt file on your server with an SFTP client such as FileZilla or similar. This is especially relevant if you have a non-WordPress site.
Once again if you’re not entirely sure what you’re doing here, there are a number of extensive guides out there to help you, as you don’t want to make mistakes with this. Here’s a link to a comprehensive guide from Google explaining exactly how you can do that.
If you don’t already have a robots.txt file within your site’s root directory, then you can use several WordPress plugins to accomplish this (covered below). However, you should look to use the root directory or a plugin, and not both.
#3
Using WordPress and Yoast SEO
A popular option is to use one of the many WordPress SEO plugins available such as Yoast SEO.
If you have this installed, go to your WordPress dashboard, select Yoast SEO and then Tools:
You can then select File editor, which will allow you to select any URLs that you do not want Google to crawl.
Once you’ve saved any changes, you can then return to Google Search Console and choose to Validate Fix on your Indexed, though blocked by robots.txt report.
If you don’t already have a robots.txt file in place, you can add a new one by selecting Create robots.txt file. This will then open a new text editor which you can edit to block search engines from crawling any areas of your site that you wish to exclude.
Once completed you can simply save your changes and Yoast will update your robots.txt file.
#4
Using WordPress and RankMath
Similar to Yoast SEO, RankMath is another tool that will allow you to edit your robots.txt file via the WordPress dashboard.
From the dashboard you can select RankMath SEO, then General Settings, and choose Edit robots.txt:
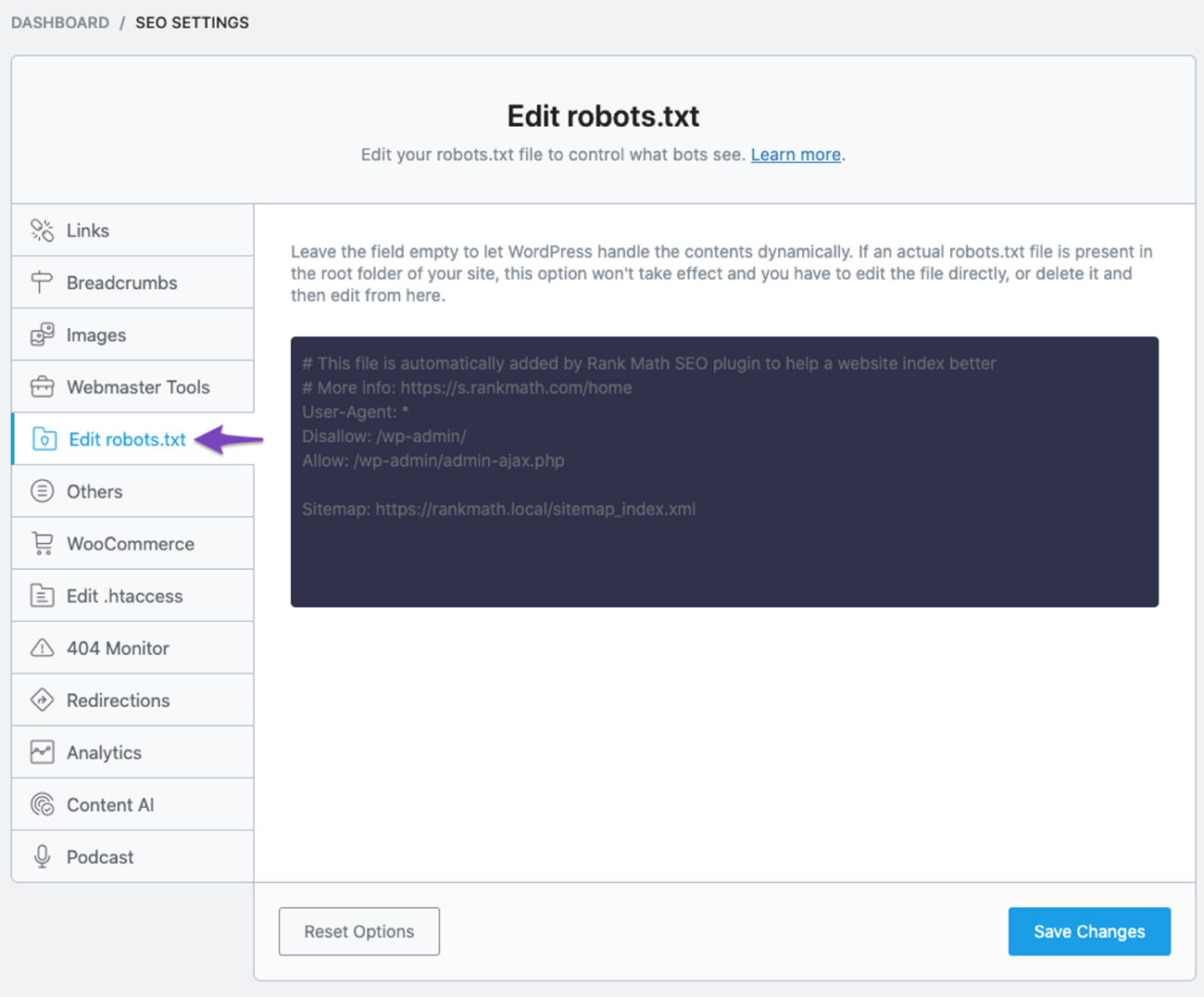
You can then look to edit the default rules that are in place to ensure that only the URLs you want to feature are included.
RankMath have created a thorough guide which we strongly suggest you follow if you’re using their tool, but have any doubts about what it is that you’re editing.
You can then save your changes and once again validite this fix within Search Console.
Two additional alternative WordPress plugins that you could use to achieve the same results are All in One SEO and Squirrly SEO.
Both are perfectly adequate and which tool you choose to use will likely come down to what you already have set up on your site.
#5
Editing robots.txt in Shopify
If you own a Shopify store they have a default robots.txt file which works well for the majority of stores.
However, if you are looking for an additional solution to this, they have created a guide on using robots.txt.liquid which actually renders the robots.txt file. There’s also an in-depth article here on how to set that up in the first place.
New Site Not Appearing in Search Results At All?
If you have a brand new site which won’t appear in Google search results at all, even after publishing new content. It may be that when setting up the site you have chosen to stop it being visible to search engines. In which case you may see the following message in your robots.txt file:
User-agent:*
Disallow:/
To correct this you can edit the options in your WordPress Dashboard.
First click on Settings, then Reading and then ensure that you do not have the box ticked which discourages search engines from indexing your site.
Summary
Ensuring that Google is able to crawl the correct pages on your site is the key to fixing this issue. By editing the robots.txt file you can make sure that Google is able to crawl any pages that you do intend to be indexed.
After all, we don’t wish to confuse Google and want to make the messages we’re sending them as clear as possible.
Monitoring the initial report in Google Search Console can also help you to identify issues early and quickly. As can using the robots.txt testing tool.
To prevent this issue from recurring, ensuring your robots.txt file is accurate and set up correctly in the first place can stop issues from arising.
Though, if you do have problems that you need to address we hope this guide has given you the tools and knowledge with which to do so.


