




I've been writing about SEO since I was 15 years old, and a decade later I'm fortunate to have consulted for companies I love like Ahrefs, Kinsta, Buffer, ConvertKit and multi-billion dollar brands.
The basics can be incredibly effective, but hundreds of sites cover them well and I want to focus on unique, creative ways to achieve better rankings.
Instead, here's my promise: I will put my absolute all into guides like this one to give original insights that help you get an edge over your competition.
That's it. That's my pitch for you to stick around (or perhaps let you know this isn't the site for you).
This is already too much text for a 'click-to-read-more-fade-thing' but there's more if you like.
Thank you for being here!
Web ‘robots’ crawl the internet looking for various pieces of data related to the services they run. Google, for instance, has a crawler which views millions of websites every single day so that when you search for something, they know the best sites to show in the results.
Some robots crawl your website to track who you link to. Some crawl your website to see what technology you’re using (or what analytics software) and then pass that information on to companies who need it.
Your robots.txt file is, as the name suggests, a text file that you can place on your web server.
This file allows you to tell robots that they can or can’t crawl certain areas of your site.

Right now, the robots.txt file for this website has the following rules:
User-agent: *
Disallow: /tweets
Disallow: /links
We’ll get into more examples in a minute, but for now let’s break this down.
First of all, the text User-agent allows me to name which crawler from the web that I’m talking to.
For example, one of Google’s robots which crawl the web is simply known as Googlebot.
In my example I used an asterisk (*) which is the symbol for a wildcard, meaning I want every single crawler that looks at my robots.txt file to follow the rules that I’ve outlined.
The disallow line tells the robots I do not want them to follow any links in the relevant folders – /tweets/ and /links/.
I picked these two specifically because on Detailed, they lead to two tools of ours that generate a lot of URLs that result in similar content, so I don’t need search engines to crawl them.
Example Robots.txt Rules
| Rule | Rule Example |
| Allow Bing.com crawlers to crawl your site but no other crawler | User-agent: Bingbot Allow: / User-agent: * |
| Don’t allow Bing.com’s crawler but allow everyone else | User-agent: Bingbot Disallow: / User-agent: * |
10 Web Crawlers and Their User Agents
A user agent is name developers assign to a web crawler so that it can be identified and, on the side of those being crawled, directed.
User-Agent: ia_archiver
This is the user agent for Amazon-owned Alexa.com.
User-Agent: facebot
This is one of a number of user-agents used by Facebook.com. When you submit a link to share on the platform, they use one of their crawlers to retrieve headline, image and similar information to help structure how a link appears.
User-Agent: YandexBot
The YandexBot is the cralwer of Yandex, the most popular search engine in Russia. You can learn more about it on our guide explaining exactly what Yandex is.
Fact Checks
 Pages Blocked By Robots.txt Can Still Be Indexed in Google
Pages Blocked By Robots.txt Can Still Be Indexed in GoogleDon’t Block Pages With Robots.txt and Noindex Directive to Deindex Them
Pages Blocked By Robots.txt Can Still Be Indexed in Google
Adding a particular URL or set of URLs to your robots.txt file does not mean that they will suddenly be removed from Google’s index, or mean that they can never appear in Google’s index.
In other words, you can still see them in search results.
Remember at the start of this guide I showed how we have some rules on Detailed’s robots.txt file that tells Google not to crawl /links/ and /tweets/.
We’ll, here’s an image that shows /links/ is actually indexed in Google:
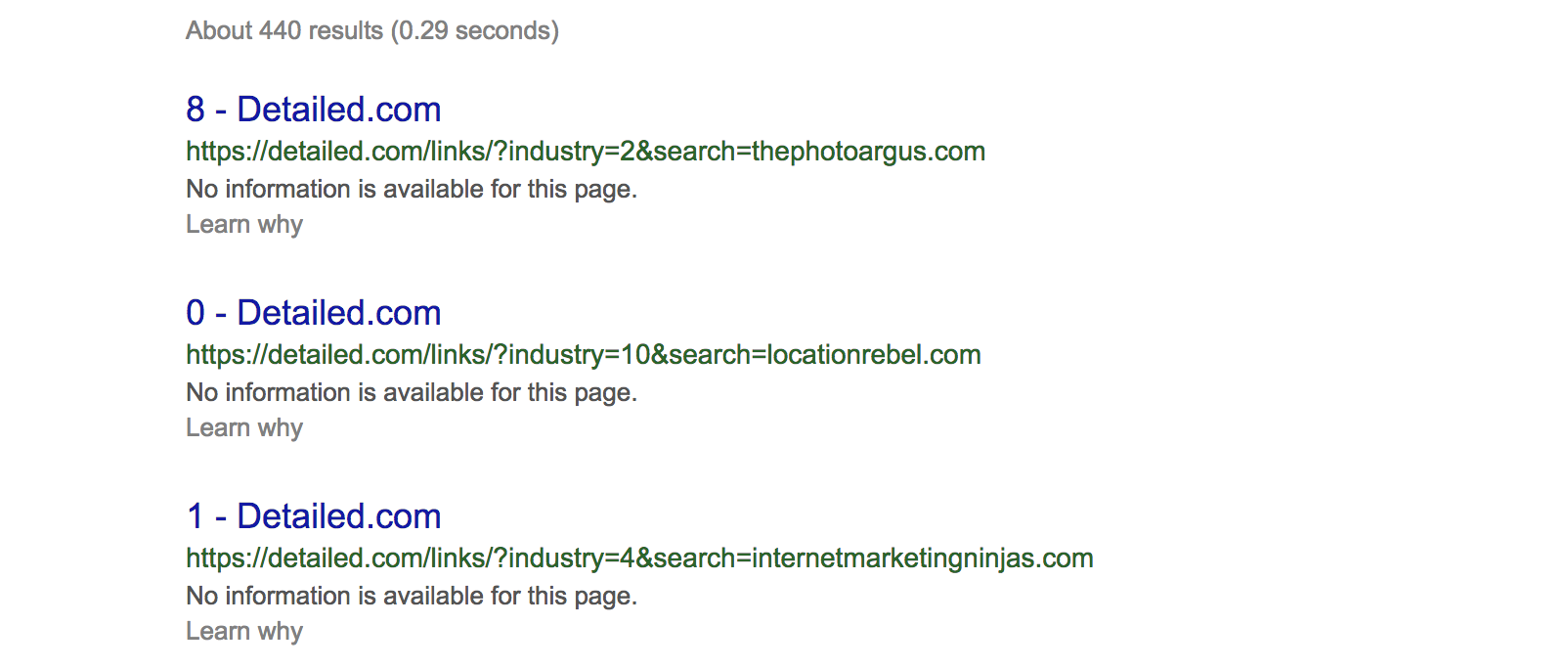
I like to be the guinea pig for any items we cover here (or, ahem, I totally forgot to noindex those pages) so there is real-world proof.
Do notice however that Google have included, “No information is available for this page.” because of the robots.txt file. We are telling them they can’t crawl those pages, but they can know that they exist.
In Google Webmaster Trends Analyst John Muellers own words,
One thing maybe to keep in mind here is that if these pages are blocked by robots.txt, then it could theoretically happen that someone randomly links to one of these pages. And if they do that then it could happen that we index this URL without any content
Don’t Block Pages with Robots.txt Then Later Add a Noindex Directive
Why?
Because then Google can’t crawl the pages and see that you’ve asked for them to be noindexed.
Google literally mark this warning as ‘Important’ in their own documentation:
For the noindex directive to be effective, the page must not be blocked by a robots.txt file. If the page is blocked by a robots.txt file, the crawler will never see the noindex directive, and the page can still appear in search results, for example if other pages link to it.
If you want to remove pages from Google’s index and you’re using the noindex directive to do so, make sure that Google are actually allowed to crawl this area of the site.


